
Mark Zuckerberg is back in the hot seat, this time facing explosive allegations that Meta deliberately swiped millions of books from notorious digital pirate sites LibGen and Anna's Archive to train its cutting-edge AI model, Llama 3.

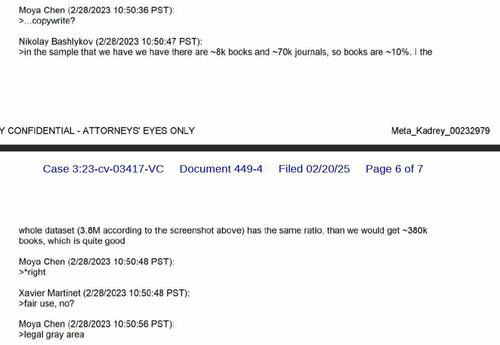
According to recently filed court documents, Meta executives were allegedly openly discussing their desperate need for high-quality content, acknowledging in a damning email, "Books are actually more important than web data." To that end, the company allegedly turned straight to piracy hubs stacked high with stolen literary treasures – without a second thought or a single cent paid to their rightful owners, according to Forbes.
The fallout has infuriated authors worldwide whose life's work may have been quietly scooped up and fed into Zuckerberg’s latest technological brainchild without credit, consent, or compensation.
As the article notes, Meta’s 2024 financial statements showcase revenues topping a staggering $164 billion, with profits nearing $62 billion. Clearly, Meta had the means and muscle to fairly compensate creators, publishers, and researchers. Instead, they allegedly chose to steal that content for training purposes.
Critics argue this saga is more than just corporate greed;
Meta’s defense, meanwhile, leans on the "fair use" argument – suggesting their AI transforms stolen content into something sufficiently new. But legal experts stress fair use typically applies to educators, reviewers, and critics – not trillion-dollar tech giants profiteering off mass commercial data harvesting.
The author of the Forbes piece checked The Atlantic's Alex Reisner’s LibGen tracking tool and made a disturbing discovery: all five of their own published books were found pirated and included in Meta’s dataset.
A major class-action lawsuit has been filed alleging copyright infringement and unfair competition – while other firms "are likely guilty of similar sins," according to the author.
Ultimately, this saga goes beyond Meta alone. The entire AI industry’s insatiable thirst for data urgently needs clear ethical guardrails. Tech giants must form sustainable, fair partnerships with content creators or risk stifling creativity, undermining intellectual property rights, and eroding public trust.
 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  Stellar
Stellar  Litecoin
Litecoin  VeChain
VeChain  Maker
Maker  Zcash
Zcash  NEO
NEO  0x Protocol
0x Protocol  Decred
Decred  Ontology
Ontology  OMG Network
OMG Network